DATA.each_line do |line| puts line end __END__ Doom Quake Diablo
关于这个技术我最喜欢的实例是使用 DATA 来包含一个 ERB 模板。它同样也可用于 YAML、CSV等等。
1 2 3 4 5 6 7 8
require'erb' time = Time.now renderer = ERB.new(DATA.read) puts renderer.result() __END__ The current time is <%= time %>.
实际上你也可以使用 DATA 来读取 __END__ 关键字以上的内容。那是因为 DATA 实际上是一个指向了整个源文件,并定位到 __END__ 关键字的位置。你可以试试看在输出之前将 IO 对象反转。下面这个例子将会输出整个源文件。
1 2 3 4 5
DATA.rewind puts DATA.read # prints the entire source file __END__ meh
多文件问题
这个技术最大的缺点是它只能用于单个文件的脚本,直接运行该文件,不能在其他文件进行导入。
下面这个例子,我们有两个文件,并且每个都有它们自己的 __END__ 部分。然而却只有一个全局 DATA 对象。因此第二个文件的 __END__ 部分刚访问不到了。
1 2 3 4 5 6 7 8 9 10
# first.rb require"./second" puts "First file\n----------------------" puts DATA.read print_second_data() __END__ First end clause
1 2 3 4 5 6 7 8 9 10
# second.rb defprint_second_data puts "Second file\n----------------------" puts DATA.read # Won't output anything, since first.rb read the entire file end __END__ Second end clause
1 2 3 4 5 6 7
snhorne ~/tmp $ ruby first.rb First file ---------------------- First end clause Second file ----------------------
# This code is from the Sinatra docs at http://www.sinatrarb.com/intro.html require'sinatra' get '/'do haml :index end __END__ @@ layout %html = yield @@ index %div.title Hello world.
sinatra 是如何实现的呢?毕竟你的应用可能是运行在 rack 上。在生产环境中你不能再通过 ruby myapp.rb 来运行!他们必须有一种在多文件中使用 DATA 的解决方案。
# I'm paraphrasing. See the original at https://github.com/sinatra/sinatra/blob/master/lib/sinatra/base.rb#L1284 app, data = File.read(__FILE__).split(/^__END__$/, 2)
最近刚切换到 Mac 平台上,感觉各种不适应。之前使用 Ubuntu 时,有 service 命令可以对服务进行管理, 但是在 Mac 系统下没有对应的工具。也许有人说可以用 launchctl 啊。但是 launchctl 的服务是开机自动启动的, 而我又不想要开机自动启动,只想在需要时启动,使用完后就停止。
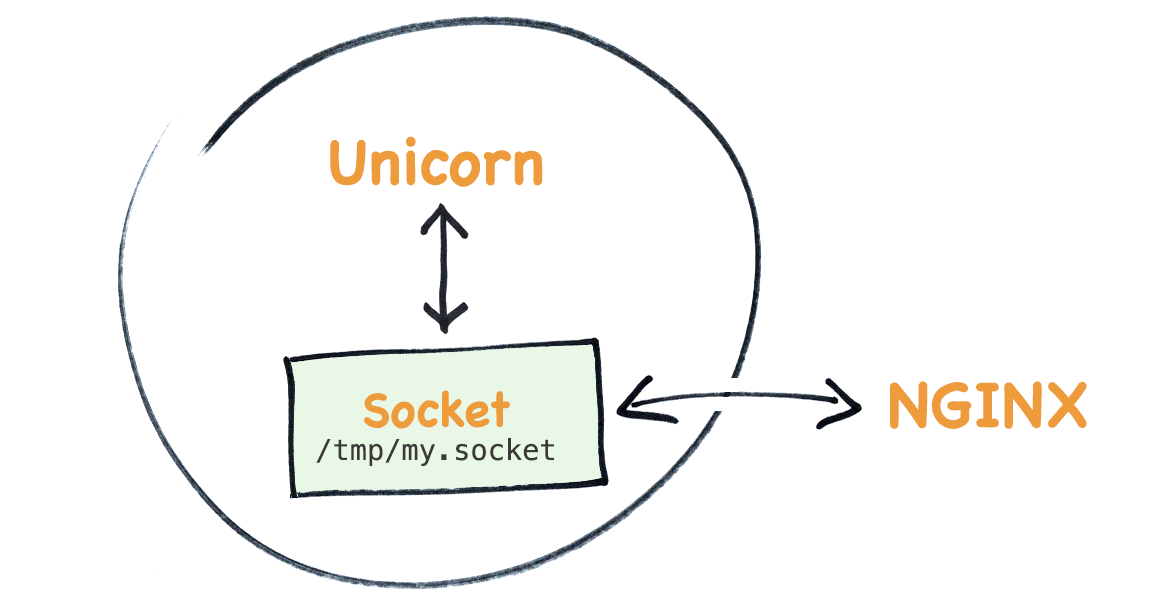
[unix_http_server] file=/tmp/supervisor.sock ; path to your socket file
[supervisord] logfile=/usr/local/var/log/supervisord/supervisord.log ; supervisord log file logfile_maxbytes=50MB ; maximum size of logfile before rotation logfile_backups=10 ; number of backed up logfiles loglevel=error ; info, debug, warn, trace pidfile=/usr/local/var/run/supervisord.pid ; pidfile location nodaemon=false ; run supervisord as a daemon minfds=1024 ; number of startup file descriptors minprocs=200 ; number of process descriptors user=root ; default user childlogdir=/usr/local/var/log/supervisord/ ; where child log files will live
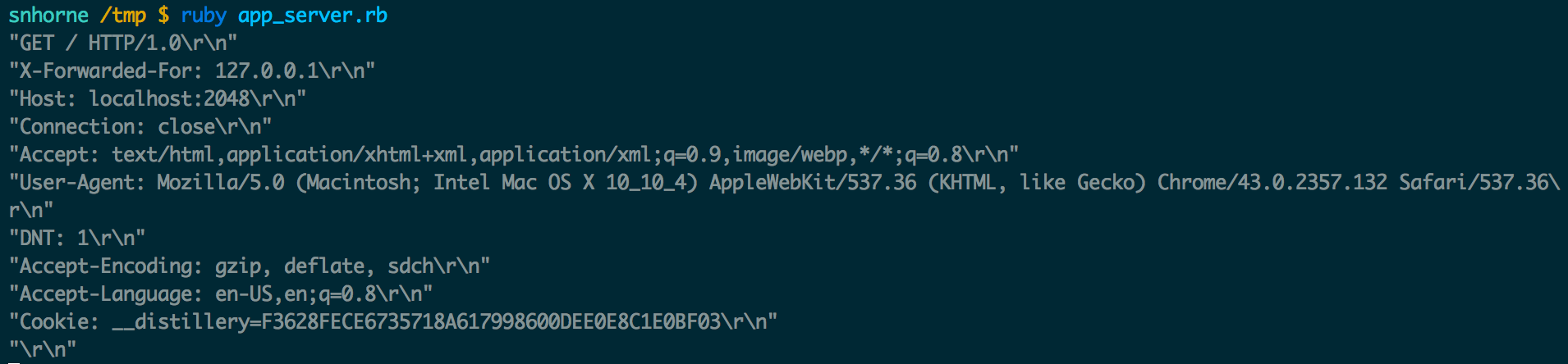
require"socket" # Create the socket and "save it" to the file system server = UNIXServer.new('/tmp/socktest.sock') # Wait until for a connection (by nginx) socket = server.accept # Read everything from the socket while line = socket.readline puts line.inspect end socket.close
# Run nginx as a normal console program, not as a daemon daemon off; # Log errors to stdout error_log /dev/stdout info; events {} # Boilerplate http { # Print the access log to stdout access_log /dev/stdout; # Tell nginx that there's an external server called @app living at our socket upstream app { server unix:/tmp/socktest.sock fail_timeout=0; } server { # Accept connections on localhost:2048 listen 2048; server_name localhost; # Application root root /tmp; # If a path doesn't exist on disk, forward the request to @app try_files $uri/index.html $uri @app; # Set some configuration options on requests forwarded to @app location @app { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app; } } }
require"socket" # Connection creates the socket and accepts new connections classConnection attr_accessor:path definitialize(path:) @path = path File.unlink(path) if File.exists?(path) end defserver @server ||= UNIXServer.new(@path) end defon_request socket = server.accept yield(socket) socket.close end end # AppServer logs incoming requests and renders a view in response classAppServer attr_reader:connection attr_reader:view definitialize(connection:, view:) @connection = connection @view = view end defrun whiletrue connection.on_request do |socket| while (line = socket.readline) != "\r\n" puts line end socket.write(view.render) end end end end # TimeView simply provides the HTTP response classTimeView defrender %[HTTP/1.1 200 OK The current timestamp is: #{ Time.now.to_i } ] end end AppServer.new(connection:Connection.new(path:'/tmp/socktest.sock'), view: TimeView.new).run